安裝BeautifulSoup4!!!
承上篇文章,我們要來分析我們爬蟲爬到的網頁,以及以自動登入it邦發表文章為例子來撰寫我們的爬蟲程式。
BeautifulSoup4的安裝:
在安裝完Python3.8的環境中,使用終端機安裝。
pip install BeautifulSoup4
or
pip3 install BeautifulSoup4
BeautifulSoup4與requests的使用
首先我們先觀察,要如何從it邦發文。
第一步登入帳號(https://member.ithome.com.tw/login )
登入後進入it幫首頁(https://ithelp.ithome.com.tw/ ) 按下發文,選擇技術文章,就可以進入草稿的頁面。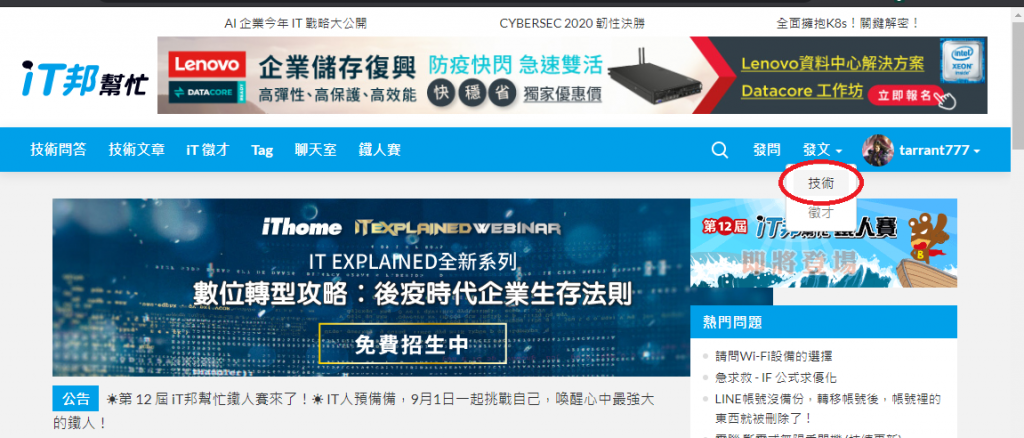
接下來使用爬蟲來登入就是我們所要面對的課題,爬蟲登入的方式有兩種,一種是使用帳號密碼登入,另一種則是利用cookies的機制來登入。我們首先先使用帳號密碼登入,這是較為直觀的方法。先打開登入帳號的頁面(https://member.ithome.com.tw/login ),並開啟Chrome的開發者模式。
選擇Network頁面。你會發現目前是一片空白。
這時按下F5或是重整頁面,我們就可以看到這個網頁與使用者的接觸方式。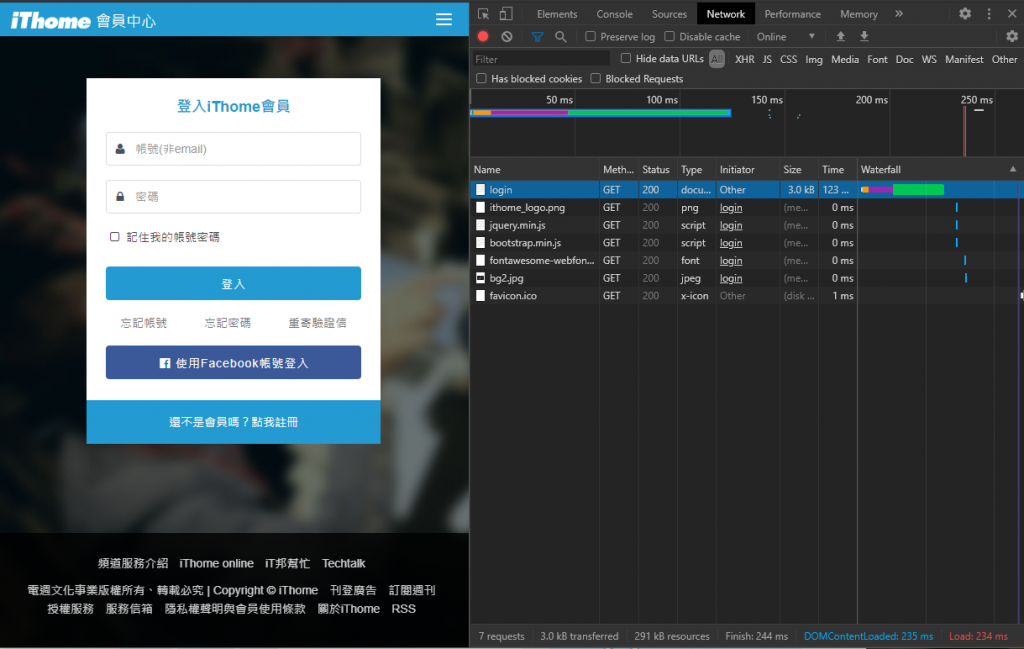
可以看到目前的頁面都是用GET這個Method拿到的,回到requests,使用GET方式來接觸網頁就會拿到login這個頁面的狀態,在這裡我們使用requests.session()讓網頁不會重新讀取,每次讀取視為同一次。
import requests
session_requests = requests.session()
#使用GET方法取得網頁資訊
result = session_requests.get("https://member.ithome.com.tw/login")
此時便可以得知網頁的資訊,用print()將資訊輸出。
print(result.status_code, result.url)
print(result.text)
result.status_code可以得到網頁狀態為200,與我們在開發者模式下看到的結果是一樣的。
result.text則可以得到此網頁的原始碼。
接下來我們回到登入的網頁按下登入,會看到登入失敗的訊息,但是在開發者頁面的Network頁面可以看到多出一個新的login網頁,而它使用的Method是POST,把頁面下拉可以看到有個Form Data欄位,這個欄位就是告訴我們在這個網頁使用POST Method所需要上傳的Data。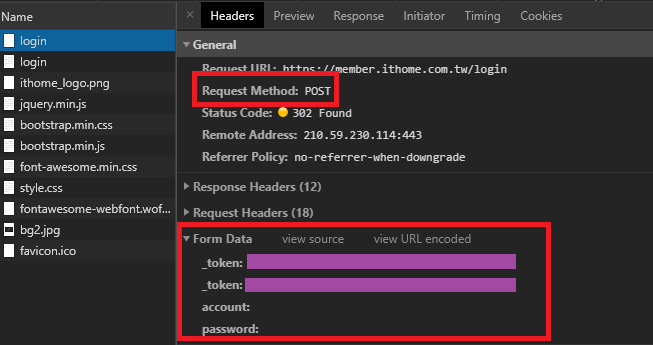
在這可以看到要達成登入的條件必須要有account(帳號),password(密碼),以及兩個神秘的token欄位。帳號,密碼註冊完我們就拿到了,所以再來便是找到神秘的token便可以搞定登入的問題。此時回到開發者模式的Elements頁面,並搜尋token,馬上就找到我們要的兩個結果了。
接下來我們要提取出我們所需要的token值,就是BeautifulSoup4上場的時間了。在上一步中我們找到了token的位置,它是處於imput類別下的一個叫"_token"的值。這裡用了比較偷吃步的技巧,因為兩個"_token"分別屬於第一個imput與第二個imput下,因此我們使用BeautifulSoup4由剛剛requests拿到的檔案做分析:
from bs4 import BeautifulSoup
result = session_requests.get("https://member.ithome.com.tw/login")
soup = BeautifulSoup(result.text, "html.parser")
BeautifulSoup4的兩個參數分別為網頁原始碼,以及分析的方式。
經過BeautifulSoup4的分析我們便可提取出我們所要的"_token"值,使用soup.find_all這個功能來找到整篇文件下的類別,剛好在這個範例中就是第一與第二個,因此我們直接使用
soup.find_all("input")[X].get("value")來取出所需要的value值。
_token_1 = soup.find_all("input")[0].get("value")
_token_2 = soup.find_all("input")[1].get("value")
兩個神秘的"_token"拿到了,配上帳號密碼,要登入的資訊已經完整了。接下來便是整理Data的時間。
login_data = {
"_token": _token_1,
"_token": _token_2,
"account": "你的帳號",
"password": "你的密碼",
}
登入所需要的資料我們都拿到了並放進字典了,接下來就是要將這包數據隨著POST Method傳給伺服器,承上篇,heads值為偽裝為一般瀏覽器的部份就不贅述。
result = session_requests.post("https://member.ithome.com.tw/login", data=login_data, headers=headers)
經過登入後,網頁會跳轉至個人的profile畫面(https://member.ithome.com.tw/profile/account/self/edit )
那至於我們要如何知道網頁會被跳轉到什麼地方呢?以下的程式碼可以讓你輕易的追蹤你要求動作造成的跳轉址位置。
if result.history:
print("Request was redirected")
for resp in result.history:
print(resp.status_code, resp.url)
print("Final destination:")
print(result.status_code, result.url)
else:
print("Request was not redirected")
將他放入我們現今的原始碼中:
result = session_requests.post("https://member.ithome.com.tw/login", data=login_data, headers=headers)
if result.history:
print("Request was redirected")
for resp in result.history:
print(resp.status_code, resp.url)
print("Final destination:")
print(result.status_code, result.url)
else:
print("Request was not redirected")
結果可以獲得:
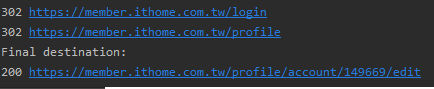
此時爬蟲便成功的登入it邦了。
發文
回到一開始在it邦首頁時選擇發文的地方,在技術上按右鍵,複製鍊結網址。這個網址便是要求伺服器給一份類似有Articl ID的草稿發文網址(https://ithelp.ithome.com.tw/articles/create?group=tech )。
使用GET取得這個網頁,起先我一直失敗,跳轉回來的網址都會是首頁,後來利用追蹤轉址的方法,發現它的跳轉是重新確認一次登入再跳回首頁,後來就明白,在這個時候再GET一次草稿發文網址就能成功了。
result = session_requests.get("https://ithelp.ithome.com.tw/articles/create?group=tech", headers=headers)
if result.history:
print("Request was redirected")
for resp in result.history:
print(resp.status_code, resp.url)
print("Final destination:")
print(result.status_code, result.url)
else:
print("Request was not redirected")
第一次執行獲得的結果會是跳回首頁。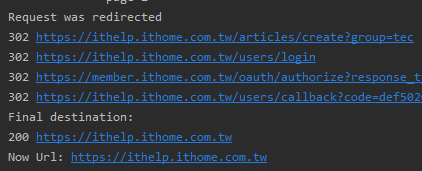
那我們就在執行第二次,寫成程式碼就是很簡單的:
result = session_requests.get("https://ithelp.ithome.com.tw/articles/create?group=tech", headers=headers)
result = session_requests.get("https://ithelp.ithome.com.tw/articles/create?group=tech", headers=headers)
if result.history:
print("Request was redirected")
for resp in result.history:
print(resp.status_code, resp.url)
print("Final destination:")
print(result.status_code, result.url)
else:
print("Request was not redirected")
print("Now Url:", result.url)
第二次的結果就成功進入草稿頁面了!
再來就是準備發文所需要的Data,在上一步我們已經取得了草稿的網址,我們先將他存在網址字串中。
Draft_Url = result.url
接下來故技重施,我們先觀察當我們在草稿頁面的時候直接按下發表文章會出現什麼事情。
開發者模式一樣選擇Network分類並按下發表文章。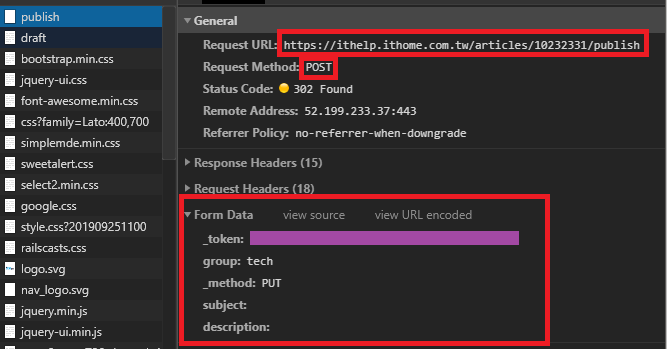
我們看到多了一個publish的網頁而且使用的是POST的方法,太好了,一樣去找FORM Data下我們所需的資料。
這次一共有五個Data需要上傳才能符合這個POST方法。分別是"_token","group","_method","subject","description"。其中"subject"與"description"分別為要輸入的標題以及內容,"group"則是創立新的技術文章時就會帶入的參數,"_method"毫無反應,就是個PUT。
所以問題還是一樣是"_token",所以找法也一樣,開啟開發者模式的Elements頁面,並搜尋"_token",發現有兩個是有值的,且值一樣。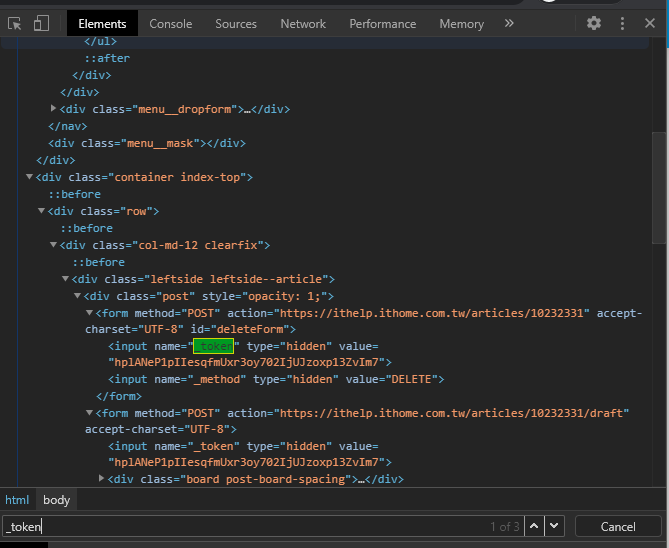
此時再度拿出BeautifulSoup4抓取我們所需的"_token"檔。
result = session_requests.get("https://ithelp.ithome.com.tw/articles/create?group=tech", headers=headers)
#經過跳轉後目前result為草稿頁面
soup = BeautifulSoup(result.text, "html.parser")
#利用soup.find找一個值
_token = soup.find("input",{"name":"_token"})["value"]
五個需要上傳的Data我們都準備完成了,我們可以看到POST方法的網址與草稿的網址只差一個是draft另一個為publish。
因此我們將剛剛存下來的Draft_Url拿出來,將draft殺掉,換上publish就是我們要上傳的網頁了。
Url_post = Draft_Url.strip("draft") +"publish"
接下來將所需的Data塞進字典:
Post_data = {
"_token" : _token,
"group" : "tech",
"_method" : "PUT",
"subject" : "你要的標題",
"description" : "你要的內文",
}
好了,萬事具備,使用POST方法上傳Data。
result = session_requests.post(Url_post, data=Post_data, headers=headers)
#若成功會跳轉至文章頁面,因此在這裡設立一個檢查點。
print("Now Url:", result.url)
NO,為什麼回傳的目前網址還是停在草稿網址呢?回到真實草稿頁面試看看,將內容與標題打進去,按下送出,一樣發生錯誤,原來是發現Form Data裡少了一個tag的欄位,所以其實總共要上傳六項數據,將它加入Post_data中就能成功了。
Post_data = {
"_token" : _token,
"group" : "tech",
"_method" : "PUT",
"subject" : "你要的標題",
"description" : "你要的內文",
"tags[]" : ['test1', "test2"]
}
綜合以上所有程式碼,完整寫出如下:
import requests
from bs4 import BeautifulSoup
session_requests = requests.session()
#使用GET方法取得網頁資訊
result = session_requests.get("https://member.ithome.com.tw/login")
soup = BeautifulSoup(result.text, "html.parser")
_token_1 = soup.find_all("input")[0].get("value")
_token_2 = soup.find_all("input")[1].get("value")
login_data = {
"_token": _token_1,
"_token": _token_2,
"account": "你的帳號",
"password": "你的密碼",
}
#上傳登入資料
result = session_requests.post("https://member.ithome.com.tw/login", data=login_data, headers=headers)
#要求發文網頁
result = session_requests.get("https://ithelp.ithome.com.tw/articles/create?group=tech", headers=headers)
#會重新確認登入並跳回首頁因此再執行一次
result = session_requests.get("https://ithelp.ithome.com.tw/articles/create?group=tech", headers=headers)
#提取_token值
soup = BeautifulSoup(result.text, "html.parser")
#利用soup.find找一個值
_token = soup.find("input",{"name":"_token"})["value"]
#此時停留在draft頁面讓draft網址獨立儲存起來
Draft_Url = result.url
#整理要上傳的data
Post_data = {
"_token" : _token,
"group" : "tech",
"_method" : "PUT",
"subject" : "你要的標題",
"description" : "你要的內文",
"tags[]" : ['test1', "test2"]
}
#將draft網頁轉為publish網頁
Url_post = Draft_Url.strip("draft") +"publish"
#將資料POST到網站上
result = session_requests.post(Url_post, data=Post_data, headers=headers)
以上便為使用resuests以及BeautifulSoup4的實做登入發文方法,在下一篇文章我們會提到如何使用docker這個好用的工具讓我們的程式可以快速部屬在任意系統上。至於cookies的登入方法,等...等到我想到再來撰寫。
 tarrant777
tarrant777
